



NVIDIA K8s Device Plugin for Wind River Linux
由Pablo Rodriguez Quesada

本文是关于在Nvidia gpu上编排容器工作负载的系列文章的第2部分。读第一部分,NVIDIA Contract Contract Runtime用于Wind River Linux.
介绍
容器的出现已经改变了计算工作负载在现代计算环境中管理和策划的方式。鉴于Paradigm转移到微服务,容器编队在当今的分布式和云系统中具有至关重要的重要性[1]。
管理成百上千的边缘设备是一项繁重的任务。幸运的是,像Kubernetes这样的协调器在平台无关的环境中消除了更新、回滚等的复杂性。[2].编排器提供了管理异构边缘集群的方法。不仅需要编排容器,还需要发现容器和编排器可以利用的硬件专用设备。不管理这些资源会导致效率低下、时间浪费、并发问题等等。
背景
在面向服务的体系结构(SOA)的上下文中,Orchestration是计算机系统和软件的自动配置,协调和管理。OrchEtration提供自动化模型,进程逻辑集中仍然是可扩展和可编译的。这种范式的使用可以显着降低解决方案环境的复杂性[3]。容器提供了一种以管理和受控方式部署软件的方便手段。控制容器的受控部署是使用Kubernetes进行的,使得在边缘完全云本机和智能,可扩展和安全性[2]。
Kubernetes
Kubernetes (K8s)是一个可移植的、可扩展的、开源的平台编排器,用于管理容器化的工作负载和服务。它促进了声明性配置和自动化[4]。
两种类型的资源形成K8S群集,主节点和工作节点。K8S主节点运行基本群集服务。工作者节点以名为POD的单位运行计划的Contained Workloads(参见下图1)。POD是可以在Kubernetes中创建和管理的最小可部署计算单元;它们封装了一个或多个共享资源的容器,包括单个IP地址[5]。
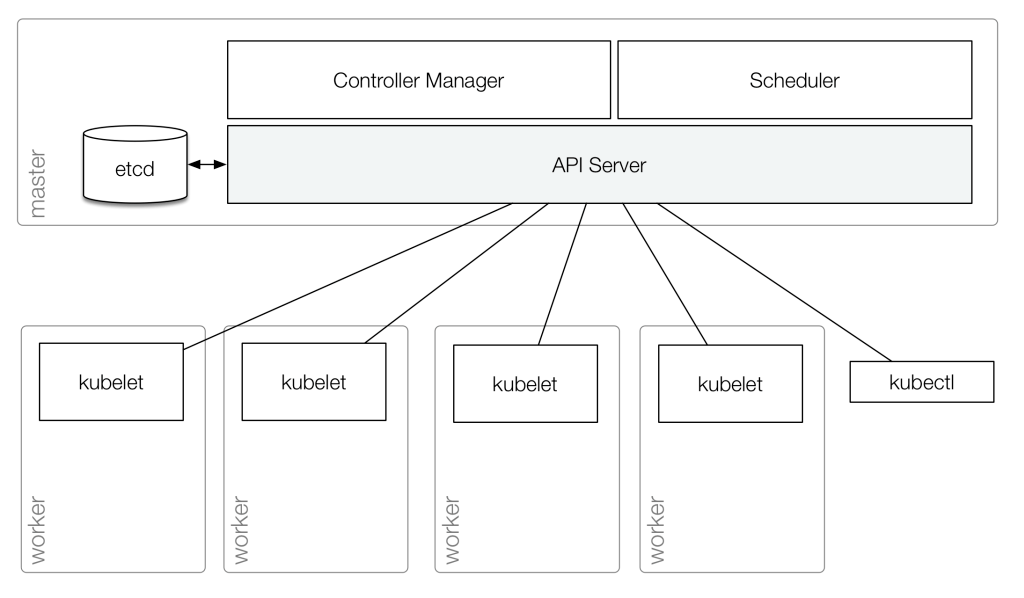
图1。Kubernetes架构概述[6]。
装置的插件
具有专用硬件的节点需要让编排器知道,以便编排器能够管理资源和控制应用程序的并发性。K8s社区开发了一种称为设备插件的接口来满足这一需求。
K8S设备插件是GRPC远程过程调用(GRPC)服务器,用于为特定的供应商特定设备添加支持。该插件允许对设备进行发现和健康检查,这允许将运行系统连接到容器中可用的设备和清理。K8S将这些服务器设计为集群的外部部分,以便它们是独立的,并且供应商可以根据其需求进行自定义它们[7]。
在设置集群时,管理员知道不同机器上有什么类型的设备,并可以安装设备插件来自动管理资源。插件检测设备并通过代码名将资源发布到K8s集群。在最终用户端,应用程序指定硬件需求,集群将应用程序分配到最佳节点[7]中的特定资源。
K3S.
在本教程中,我们使用K3s,一个由Rancher Labs开发的K8s定制发行版,其重点是边缘。它有很多改进,使它适合于这个项目;例如,它是轻量级的,封装在一个二进制文件中,这使得它适合嵌入式[8]。
K3S优惠的另一个增强是安装在SQLite3之上的轻量级存储后端,并最小化的依赖性版本。这些依赖项为嵌入式世界量身定制,包括K8S群集的所有基本功能。例如,Rancher Labs开发了它的存储驱动程序,称为本地路径配置程序,可以使用各个节点上的本地存储在框中创建持久卷声称的能力[8]。这些改进和更多使牧场主版本的K8s适合本教程的需求。
nvidia容器编排
用于K8s的NVIDIA设备插件是一个守护进程集,它允许集群自动公开每个节点上可用的GPU数量,跟踪运行状况并在K8s集群中运行启用GPU的容器。要使用这个插件,必须在节点中安装NVIDIA-docker堆栈,以及NVIDIA和CUDA驱动程序[9]。该插件自动执行与集群的注册和通信,以便集群的用户可以请求其荚内的GPU资源。
这个插件的一个限制是它只支持在Intel 64位架构上运行的Kubernetes集群。因此,在嵌入式基于arm的设备或NVIDIA Jetson设备[9]上编排容器是不可能的。本文使用了一个定制的设备插件,允许在Jetson板上使用NVIDIA gpu。通过修改现有的插件以支持其他架构,并使用修改后的源代码创建一个ARM64容器,我们可以协调基于Intel和arm的节点。
优先遗嘱
本文是关于在Nvidia gpu上编排容器工作负载的系列文章的第2部分。读第一部分,NVIDIA Contract Contract Runtime用于Wind River Linux.
我们假设一个启动的Jetson Board有以下要求:
- nvidia司机= 384.81
- nvidia-docker版本> 2.0(参见如何安装和它
先决条件) - Docker配置了nvidia作为默认运行时。
- Kubernetes版本> = 1.10
- 风河Linux >= LTS 19
资料来源:[9]
风河Linux图像
对于OS映像,请务必将以下包添加到项目中:
- docker-ce
- git
- openssh
安装k3
以下脚本下载最新版本的K3可用;但请注意,本教程使用版本V1.18.2 + K3S1k3。
mkdir -p /usr/local/bin curl - sfl https://get.k3s.io | sh -安装后,检查状态:
kubectl得到节点示例输出:
root@jetson-nano-qspi-sd:~# kubectl get nodes NAME STATUS ROLES AGE VERSION jetson-nano-qspi-sd Ready master 88s v1.18.2+k3s1更改K3S默认运行时
要使用NVIDIA运行时,添加Docker作为默认的容器运行时:
Sed -i 's/server \\/server——docker \\/' /etc/systemd/system/k3 . conf . confService systemctl daemon-reload systemctl restart k3s然后,通过修改文件将nvidia容器运行时添加为默认Docker运行时:/etc/docker/daemon.json.如下:
{“runtimes”:{“nvidia”:{“路径”:“/ usr / bin / nvidia-container-contractime”,“runtimeargs”:[]}},“默认运行时”:“nvidia”}然后,重新启动Docker守护程序:
systemctl重启码头工人安装NVIDIA K8s Device Plugin
要使设备插件在ARM64架构上工作,我们需要使用以下修补程序编辑NVIDIA设备插件:
- 0001-ARM64-Add-Support-For-ARM64-Carchitectures.patch
- 0002 - nvidia -添加-支持- - tegra boards.patch
- 0003-main-add-support-for-tegra-boards.patch
克隆原来的NVIDIA设备插件repo并应用以下补丁:
$ git clone -b 1.0.0-beta6 https://github.com/nvidia/k8s-device-plugin.git $ cd K8s-device-plugin $ wget https://labs.windriver.com/downloads/0001-ARM64-Add-Support-for-Arm64-Architectures.Patch $ Wget HTTPS://labs.windriver.com/downloads/0002-nvidia-add-support-for-tegra-boards.patch $ wget https://实验室。windriver.com/downloads/0003-main-add-support-for-tegra-boards.patch $ git am 000 * .patch然后,构建设备插件容器:
$ docker build -t nvidia/k8s-device-plugin:1.0.0-beta6 -f docker/arm64/Dockerfile.ubuntu16.04接下来,将容器部署到您的集群中:
$ kubectl应用-f nvidia-device-plugin.yml最后,检查pod的状态,直到它们都在运行:
$ kubectl得到pods -adevice插件的输出示例如下:
root@jetson-nano-qspi-sd:~/test/k8s-device-plugin# kubectl logs NVIDIA -device-plugin-daemonset-k8g57——namespace=kube-system 20/05/29 19:49:07 NVIDIA Tegra device detected!20/05/29 19:49:07启动FS watcher。20/05/29 19:49:07启动OS watcher。20/05/29 19:49:07检索插件。20/05/29 19:49:07启动GRPC server for 'nvidia.com/gpu'sock 20/05/29 19:49:07用Kubelet注册'nvidia.com/gpu'的设备插件结果
在安装步骤之后,您将拥有一个额外的Kubernetes节点nvidia.com/gpu.资源:
$ kubectl描述节点…已分配的资源:(总限制可能超过100%,即过度使用。)资源请求限制-------- -------- ------ cpu 100m(2%) 0(0%)内存70Mi (1%) 170Mi (4%) ephemeral-storage 0 (0%) 0 (0%) hugepages-2Mi 0 (0%) 0 (0%) nvidia.com/gpu 00 0…NVIDIA容器运行时超过K8s
通过部署以下pod,查询GPU设备来验证NVIDIA运行时是否正常工作:
$ cat << eof> query_pod.yml apiersion:v1种类:pod元数据:名称:query-pod规范:Restartpolicy:Onfailure Containers: - 图片:Jitteam / DeviceQuery姓名:Query-Ctr Resources:限制:NVIDIA.com/GPU:1 eof.$ kubectl应用-f query_pod.yml检查POD的状态query_pod.并等到平等“完全的”:
$ kubectl get pod query_pod然后,检查日志:
$ kubectl logs query_pod输出:
root @ jetson-nano-qspi-sd:〜/ k8s-device-plugin#kubectl logs pod1 ./devicequery启动... cuda设备查询(运行时api)版本(Cudart静态链接)检测到1个CUDA功能设备设备0:“nvidia tegra x1”该容器正确检测到1个CUDA设备!
GPU并行
测试GPU资源的并发正常处理:
Cat << Eof> Concurrency.yml apiversion:V1类型:Pod元数据:名称:POD1规范:RESTARTPOLICY:ONFAILURE CONTEXERS: - 图片:NVCR.IO/NVIDIA/l4t-base:r32.4.2名称:POD1-CTR命令:[“睡眠”] args:[“30”]资源:限制:nvidia.com/gpu:1 --- apiersion:v1种类:pod元数据:名称:pod2规格:restartpolicy:onfailure容器: - 图片:nvcr.io/nvidia / l4t-base:r32.4.2名称:pod2-ctr命令:[“睡眠”] args:[“30”]资源:限制:nvidia.com/gpu:1 eof应用更改并检查第二个POD的状态:
kubectl应用-f concurrency.yml kubectl描述pod pod2输出:
root @ jetson-nano-qspi-sd:〜/ k8s-device-plugin#kubectl描述pod pod2 ...事件:键入消息的理性年龄---------------------警告失败了<未知>默认调度器0/1节点可用:1个不足的nvidia.com/gpu。警告失败,<未知>默认调度程序0/1节点可用:1个不足的nvidia.com/gpu。如您所见,第二个POD未能分配GPU,因为第一个POD已经使用它。一旦POD1.存在,另一个荚果成功运行。
在等待30秒(指定的超时时间)之后,您将看到以下输出:
root @ jetson-nano-qspi-sd:〜/ k8s-device-plugin#kubectl描述pod pod2 ...事件:键入消息的理性年龄---------------------警告失败了<未知>默认调度器0/1节点可用:1个不足的nvidia.com/gpu。警告失败,<未知>默认调度程序0/1节点可用:1个不足的nvidia.com/gpu。正常计划<未知>默认调度程序已成功分配默认/ pod2到Jetson-nano-qspi-sd正常拉6s kubelet,jetson-nan-qspi-sd容器图像“nvcr.io/nvidia/l4t-base:r32.4.2”已经存在于机器正常创建的6S Kubelet,Jetson-Nan-QSPI-SD创建的容器POD2-CTR正常启动5S Kubelet,Jetson-Nan-QSPI-SD启动了集装箱POD2-CTRroot@jetson-nano-qspi-sd:~# kubectl get pods NAME READY STATUS restart AGE pod1 0/1 Completed 0 2m38s pod2 0/1 Completed 0 2m38s结论
与K8s一起使用的设备插件允许对GPU启用的设备进行编排,并纠正了之前面临的并发问题。设备插件有效地支持外部设备的发现,因此容器可以利用不同类型的硬件加速器。现在,使用最先进的技术来管理GPU工作负载是可能的,因此,使HPC领域,如AI受益于这种加速。
参考文献
[1] A. M.Beltre,P. Saha,M.Govindaraju,A. Younge和R. E. Grant,“使用Kubernetes容器编排机制启用云基础架构的HPC工作负载”2019年IEEE / ACM International Worksshop Containers和New Orchestration在HPC中孤立环境(Canopie-HPC), 2019,第11-20页。
[2] C. Tarbett,“为什么K3S是Edge kubernetes的未来,”
牧场主实验室,2019年11月。
[3] T. ERL,面向服务的架构:概念,技术和
设计.美国:普伦蒂斯霍尔PTR, 2005。
“Kubernetes是什么?”2020。
[5] M. E.Piras,L. Pireddu,M. Moro和G. Zanetti,“容器
HPC集群中的编排,“SpringerLink2019年6月,第25-35页。
Kubernetes:第1部分架构和主要组件概述,https://rtfm.co.ua/en/kubernetes-part--arectitionure-and-main-components-overview/
RTFM:Linux,DevOps和系统管理.5 - 2020。
[7] Kubernetes,“社区”GitHub..2020。
[8]“K3S - 5小于K8s”,“牧场主实验室.4月20日。
[9] NVIDIA,“K8S-Device-Plugin”GitHub..5 - 2020。
所有产品名称,徽标和品牌都是其各自所有者的财产。
本软件中使用的所有公司,产品和服务名称仅用于识别目的。Wind River是Wind River Systems的注册商标。
担保声明/不支持:根据风河标准软件支持和维护协议或其他方式,风河不为本软件提供支持和维护服务。除非适用法律要求,风河公司提供软件(和每个贡献者提供其贡献)在“是”的基础上,没有任何种类的保证,无论是明示的或暗示的,包括但不限于,所有权,不侵权,适销性,或适合特定目的的任何保证。您完全有责任决定使用或重新分发软件的适当性,并承担与您行使许可证下的许可相关的风险。
Docker是Docker,Inc。的商标
Kubernetes是Linux基金会的商标。
NVIDIA,NVIDIA EGX,CUDA,Jetson和Tegra是美国和其他国家的NVIDIA公司的商标和/或注册商标。其他公司和产品名称可能是与其相关的各项公司的商标。